
Don't Mock What You Don't Own
Published: 2018-04-02
Tagged: programming learning architecture guide
Mock-heavy development
Mocking is helpful, but it also gives you enough rope to hang yourself. Mocks have pushed me into some bad testing patterns, one of which is popular enough to merit its own rule: "Don't mock what you don't own." It's simple, but it changes how you organize your code forever.
As I added more mocking to my work-flow, several patterns became distinct:
- Using more than two mocks made it hard to discern what was actually tested.
- Having multiple mocks in one test incentivized me to skip refactoring and dump more code into the method and test because adding one more mock was easy.
- Even when tests were green and promised 100% coverage, the code would break in production.
Using too many mocks made the dependencies between modules unclear, which lead to poor interface design and isolation. This process worked slowly, starting with 1-2 mocks for some low-level module. As these modules were integrated, that number rose to 4-5, even 8+ on the highest abstraction level. Having read Robert Martin's articles on Clean Architecture, I realized with horror that the high-level business logic was dependent on low-level implementation details. That's the complete opposite of good design, where the low-level details rely on high-level business logic to work. In a car factory, the CEO isn't dependent on the car welding robot's decisions, the robot is dependent on the CEO's decisions.
It's best to illustrate this problem with an example method that retrieves and processes data:
# some_module
def get_test_results(api_url, month):
results = requests.get(api_url, {'month': month})
processed_results = [result for result in results if result['official'] == True]
return processed_results
And the test:
# using pytest and pytest-mock
def test_get_test_results(mocker):
mock_get = mocker.Mock()
mock_get.return_value = [{'official': True, 'result': 'PASS'}, {'official': False, 'result': 'FAIL'}]
mocker.patch('some_module.requests.get', mock_get)
results = some_module.get_test_results('http://example.com', 'JAN')
assert results == {'official': True, 'result': 'PASS'}
mock_get.assert_called_once_with('http://example.com', 'JAN')
The code is short and the test passes, but what will happen if the requests library was upgraded and its get method signature changed? The code would fail in production at some random time in the future, yet the tests would still pass. What if the HTTP API the code interacts with is flaky? Retry/timeout logic needs to be added. This can be done by passing in a Session object that takes care of this:
def get_test_results(api_url, month, session):
results = requests.get(api_url, session, {'month': month})
processed_results = [result for result in results if result['official'] == True]
return processed_results
Following that, the test grows:
# using pytest and pytest-mock
def test_get_test_results(mocker):
mock_get = mocker.Mock()
mock_session = mocker.Mock() # I'm avoiding using pytest fixtures for brevity
mock_get.return_value = [{'official': True, 'result': 'PASS'}, {'official': False, 'result': 'FAIL'}]
mocker.patch('some_module.requests.get', mock_get)
results = some_module.get_test_results('http://example.com', 'JAN', mock_session)
assert results == {'official': True, 'result': 'PASS'}
mock_get.assert_called_once_with('http://example.com', 'JAN')
The tests pass and the code is automatically deployed to production thanks to CI/CD. A few hours later the new code runs and fails. Where's the error?
The arguments to requests.get are in the wrong order. The correct call is requests.get(api_url, {'month': month}, session=session). It's a simple, human mistake to make, but the test didn't catch it, because it's focused on testing one thing - the filtering logic. This is a hint that this functionality should be split into two methods and two tests: one for filtering and one for integrating the requests API. More on this later.
As time goes by, new feature requests keep coming in and the function signature looks like this:
def get_test_results(api_url, month, session, authenticator, data_validator):
# body omitted for brevity
Each addition increases the time needed to refactor this code, so the method grows and so does the test. A mock_authenticator and mock_data_validator are added, hiding more dependencies, and making the problem described above more likely to happen. Those sighs of frustration? it's the sound technical debt makes when it grows.
Chinese Finger Trap

This pattern reminds me of the Chinese finger trap. It initially slips through code review unnoticed, and as changes introduce more mocks, it becomes harder to escape. Soon, developers learn to avoid the long, convoluted code. That is, until one day it breaks, and everybody is angry and tired.
The trap can be disarmed by moving the dependency into its own class or module, making it a wrapper or adapter. Looking at the example code above, this means moving the requests.get part into its own class, "FlakyAPIAdapter." The new class is responsible for interfacing with requests properly: supplying the right arguments, configuring timeouts, and handling retries. Another feature of FlakyAPIAdapteris that it defines an interface that is owned by the project and that other project code can depend on - it "breaks" the dependency on requests.
Learnings
Too many mocks are a code smell. They indicate a piece of code either doing too many things or depending on too many things. Can this code be broken up into smaller pieces to decrease the number of mocks? Are the pieces all on the same level of abstraction? Is it even the right level of abstraction?
This anti-pattern occurs most often on the boundary between a project's code and a 3rd party dependency. Keep this in mind to spot it early.
The broadest fix for this is the inversion of control principle. The trap is sprung by making the project's code depend on a 3rd party dependency:
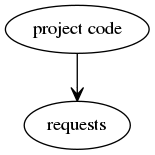
Wrapping the 3rd party module in a wrapper inverts this dependency by creating an interface between these two pieces of code:
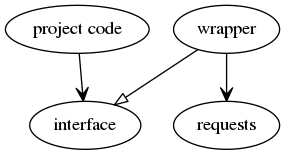
This results in the project depending on the interface and the wrapper code implementing that interface. In other words, the wrapper keeps the project code safe from changes in the 3rd party dependency.
The resulting unit tests are fast and safe. Fast, because they depend on a fake object that doesn't do any IO. Safe, because the fake object implements the project-owned interface. Integration tests are used to test the wrapper. They take longer to run, but they're only run sporadically, like when the 3rd party dependency changes.
Comments