
PlaidCTF 2015 - Corrupt PNG
Published: 2015-04-20
Tagged: hacking
This was a fun task and challenging on many levels. No simple way to "trick" that flag out of it, but rather, slowly building an idea of the problem and trying to script a solution.
We are given a PNG file (it's always a PNG file, isn't it?) that's, well, corrupt. Can't view the image. Running pngcheck -v on it we get:
File is CORRUPTED. It seems to have suffered DOS->Unix conversion
At this point I didn't know what this really meant so I searched anything related and aside from the excellent wiki article that sort of pointed me towards the right idea (A DOS-style line ending (CRLF) to detect DOS-Unix line ending conversion of the data.), I found this SO answer that really told me what was going on.
Basically, DOS and *nix systems have different ways to signal an end of line in a text file. DOS uses \r\n or 0x0d 0x0a in hex whereas *nix uses just \n or 0xa. If we look at the first few bytes of the corrupted file, we indeed see that the 0x0d 0x0a sequence was mutilated to just 0x0a. After inserting a 0x0d byte there and thinking all is well and good (I was sleepy), I ran pngcheck -v again and lo and behold! Error in the IDAT chunk. Running pngcheck -vf to force check the remainder of the file showed me that all remaining IDAT chunks were corrupted in various ways. No wonder, all of the existing 0xd0a bytes were replaced with 0x0a bytes. Everything is messed up! What's worse, each chunk contains ~400 0x0a bytes. Not all of them were initially 0x0d 0x0a. How do you know which bytes to replace with 0x0d 0x0a and which bytes to leave alone?
You can check the chunk length block in front of each block. Add it to the offset of the first byte after the IDAT tag for that chunk and jump to that location in the file and see where you land. The next chunk starts with the same length, so you're looking for a sequence of bytes that look like 0x00 0x02 0x00 0x00. You probably landed too far, probably into the chunk length block of the next block. Each byte too far means a 0x0d 0x0a sequence shortened to 0x0a. If you land 2 bytes too far, you have to find two poor 0x0a bytes that need a 0x0d partner. You have 400 choices. Doing this by hand would take ages.
Never fear! CRC is here (please excuse the lame dad jokes)! The last four bytes of each IDAT section are a CRC error checking sequence. These CRCs haven't been damaged so we could place 2 0x0d bytes by some 0x0a bytes, run the data block (no tag, no CRC sequence, no lengh chunk, just the data block) of each IDAT section, and compare CRCs. If we find a match, we restored a block!
Find the right combination of bytes to pair up takes a second if a data block is missing one byte. 30 seconds if it's missing two bytes. 15-25 minutes if it's missing 3 bytes. My simple script checks all the combinations instead of quitting when it finds the right one, so a lot of time would be saved if the script quit when it hit gold. Thankfully, we're missing at most 3 bytes in two IDAT sections, and 1-2 bytes in the remaining 4-5 sections.
I dd'd each data block from each IDAT section, noted the CRC code and the number of missing bytes. I found all of the offsets (or indexes) of all the 0x0a bytes in each data block. Then I ran it through python's itertools combinations function using the number of missing bytes as r like so: combinations(offsets, 2) for a block missing 2 bytes.
Finally, I did some python bytearray slicing magic to replace 0x0as with 0x0ds according to the combinations of offsets I got earlier. I CRC'd each modified bytearray and compared it against the known good CRC code to see if this combination of offsets and replaces was correct. Note! At first I was comparing CRC's directly until I noticed that my CRC code wasn't prepending a 0 at the front of a CRC ie. I was getting 0xfaf8030 instead of 0x0faf8030 and my script wasn't working. So instead of changing my CRC into hex using hex(), I changed the data block's CRC into an int using int(crc, 16). Suddenly I was getting hits!
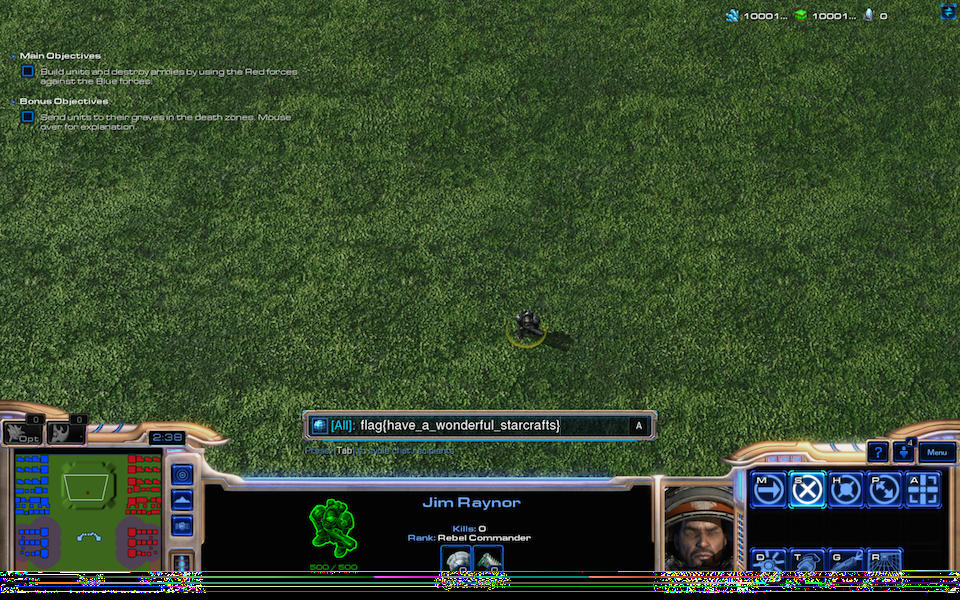
At the end, I took the resulting offsets, jumped to those places in the file and appended 0x0ds and IDAT by IDAT, I got a fixed PNG with the flag!
JPEG of the fixed PNG:
And here's the script I used to fix each block (note - it's shitty and unwieldy, as you have to manually change the file name, the number of missing bytes, and a block's target CRC, but it worked!):
#!/usr/bin/env python
import zlib
import binascii
from itertools import combinations
from multiprocessing import Pool
TAG = 'IDAT'
CRC1 = '0xf55a745d' # (549,)
CRC2 = '0x06e15ebf' # (498, 26270, 125127)
CRC3 = '0xa0bdc18a' # (71422,)
CRC4 = 'gut' # all good here
CRC5 = '0x09c557f7' # (9614, 51469, 67846)
CRC6 = '0x0848d2c4' # (100439,)
CRC7 = '0x295c44c9' # (88343, 120992)
CRC8 = 'gut' # all good here
CRC9 = '0x2fad0fb3' # (112262,)
def get_crc(tag, data):
ch1 = zlib.crc32(tag) # this isnt necessary but shows
ch2 = zlib.crc32(str(data), ch1) # a cool property of CRC
return ch2 & 2**32-1
def comparator(crc, int_crc):
return int(crc, 16) == int_crc
#return crc == hex(int_crc)
chunk = open('corrupt_chunk6', 'rb')
ff = chunk.read()
bray = bytearray(ff)
print 'chunk length: {}'.format(len(ff))
#print hex(get_crc(TAG, ff))
#print hex(get_crc(TAG, bray))
offsets = [i for i, ltr in enumerate(ff) if ltr == '\x0a']
combs = list(combinations(offsets, 1))
def f(truple):
bz = bray[:]
for j in [0]:
bz = bz[:truple[j]] + bz[truple[j]:].replace('\x0a', '\x0d\x0a', 1)
#import pdb; pdb.set_trace()
return comparator(CRC6, get_crc(TAG, bz))
#results = [f(i) for i in combs]
pool = Pool(processes=4)
results = pool.map(f, combs)
offsetz = [i for i, ltr in enumerate(results) if ltr]
print len(offsetz)
for i in offsetz:
print combs[i]
Comments