
Programming Collective Intelligence chapter 4 notes
Published: 2014-04-10
Tagged: python readings guide
Chapter 4 of Programming Collective Intelligence (from here on referred to as The Book) jolts us with a hefty dose of holy crap this is awesome and "holy crap, how the hell does this even work?" by serving us knowledge how to build a search engine... And how to use a neural network to improve the results. The code is pretty prototypical, but the principals are what counts and you can learn a huge deal about machine learning from this one chapter. As a side note, I noticed that doing Andrew Ng's Coursera Machine Learning course really helps to follow along some of the more intricate reasons why this works. It's cool to know what happens inside that black box we're going to build.
The chapter is divided into four parts:
- How to crawl sites and how to store the data.
- How to search through this data to satisfy a query.
- How to rank the results.
- How to build a neural network that aids in ranking results.
That's a lot of ground to cover so again I annotated the code liberally to make it as easy to follow as possible. Since The Book doesn't go into the mathematical details on how neural networks work, I've also left these details out. All the code for this chapter is available here.
Web Crawling
The first step towards building a search engine is how to have our script visit web pages by itself using only the links on these pages. The second step is to store the information in a way that will be easy to analyze.
To go through this example, The Book provides us with a crawlable directory of HTML documents at the author's own site. In order to make crawling faster and as a way to avoid the disappearance of that website, I've made the offline version available for download. Using the offline version requires an extra step, because the links in the documents are relative and my setup had issues with linking from one document to another. To solve this problem in Linux or OSX, open up a terminal in the uncompressed wiki/ directory and enter this bit of Linux magic:
find ./ -type f -exec sed -i 's@wiki@home\/user\/python\/collective-intelligence\/chap4\/wiki@g' {} \;
This will use sed to change every link in every file to the absolute system path. In order for this to work, you have to change the second part of the expression (between the 2nd and 3rd '@') to the absolute path of the uncompressed files. Having to do this introduced me to sed and I can't imagine my life as a developer without having this awesome tool in my toolbox. This is a great resource to learn more about this awesome tool.
However, if you things aren't working and you don't want to devote more time to figuring things out, then you can download the ready database.
The crawling code works by starting out at a single link, using BeautifulSoup to scrape all the links off of that page. Then it checks if each link is valid and if it's been discovered before. If not, then it's added to the list of links to crawl. We also save all the human readable text from every page along the way too. This process is repeated until the list of links is exhausted.
To initiate the crawling process, execute these commands in an interactive interpreter session (warning: this takes about 3-4 minutes using the offline version and probably quite a bit more using the online version):
In [1]: import searchengine
In [2]: crawler = searchengine.Crawler('index.db')
In [3]: crawler.create_index_tables()
In [4]: pages = ['file:///home/user/python/collective-intelligence/chap4/wiki2/wiki/Categorical_list_of_programming_languages.html']
In [5]: crawler.crawl(pages)
The most interesting part of this is how the crawler stores the data it collects:
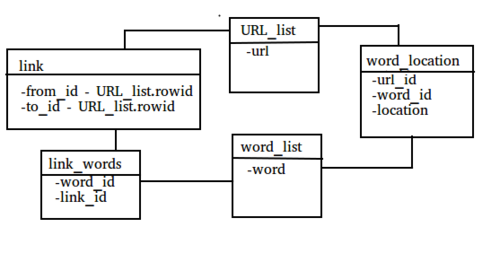
url_listandword_liststore all the crawled urls and words and are the foundation of our database.word_locationnot only tells us with which url a word is associated but also where it is on that page thanks to a location column. The location column is an integer that shows how far the word is from the beginning of the page. This allows us to analyze our pages by inspecting their contents such as word frequency, word location, or word distance.linkstores everything we need to know about a link - where is it linking from and where is it linking too.link_wordsstores what words are related to a specific link (link text). Having this and the previous point, we are able to analyze our page by the inbound link score, link test score and finally - PageRank.
Searching our database
How do we actually search through that database? First we must gather all of the urls related to the words present in the query. Then we have to rank them, but I'll go over that in the next section.
The get_match_rows function is how we obtain all of the urls related to all of the words present in the query. First we go through the word_list table and we obtain the unique id of that word.
Then we want to go through the word_location table to gather both the url under which the word can be found as well as the location of the word for that url. To accomplish this, our script actually builds a pretty intricate SQL query. A two-word query looks like this:
select w0.url_id, w0.location, w1.location from word_location w0, word_location w1
where w0.url_id = w1.url_id and w0.word_id = 113 and w1.word_id = 929;
This returns a list of rows with all of the information we need - the url and the location for each query word. We can invoke this function before we tackle the issue of ranking the scores like this:
In [5]: searcher = searchengine.Searcher('searchdb2.db')
In [6]: rows, word_ids = searcher.get_match_rows('functional')
Ranking the results
At this point, we have a huge list (possibly over 10 thousand rows!) of all the urls and locations associated with the query as well as the query word's id's. While nice to have, this far from having information that we, humans, can use.
This is where get_scored_list comes into play. This function will apply the weights to all of the rows and return a ranked list with the results we probably really want at the top. The weights list itself is populated by tuples in the form of (weight strength, scoring function result). I've commented out some possible weight lists in the file, but it's fun to check out how each one will change the results that we're getting back.
In [18]: scored_list = searcher.get_scored_list(rows, word_ids)
scored_list is actually a dictionary with {url: score} pairs. If we sort it, we'll see which url has the highest score:
In [34]: sorted(scored_list.items(), key=lambda score: score[1], reverse=True)[0:5]
Out[34]:
[(220, 3.3181457129368304),
(2, 1.0738900218537795),
(1, 0.5068374788510106),
(289, 0.42755736882910844),
(227, 0.41145496256711767)]
# let's check this url id's
In [35]: searcher.get_url_name(220)
Out[35]: u'file:///home/fogg/python/ml/collective-intelligence/chap4/wiki/Functional_programming.html'
In [36]: searcher.get_url_name(2)
Out[36]: u'file:///home/fogg/python/ml/collective-intelligence/chap4/wiki/Programming_language.html'
In [37]: searcher.get_url_name(1)
Out[37]: u'file:///home/fogg/python/ml/collective-intelligence/chap4/wiki/Categorical_list_of_programming_languages.html'
Those look pretty good. Why not try it out with one of the other functions:
- Frequency score - check how often a word appears under a given url. Search engines back in the day used to use this method. It worked good and all until someone made another website that had more cool words than yours, then he's no. 1. People quickly found ways to exploit this by e.g. adding in lots of white words on a white background.
- Location score - checks how close to the beginning of the document the query words are. This makes a lot of sense - when you're writing about something, you usually tend to describe it up front.
- Distance score - checks how close the query words appears in a document. When querying for "cat toys", it makes sense for pages that describe "cat toys" be ranked higher than pages that describe "cat (...) toys".
- Inbound links count score - rank a page by how many other pages link to it. If this count is high, it might mean that many people reference it and so the content is of good quality.
- Inbound links text score - rank a page by the inbound link text. A link is better if it says "Great cat toys here" and worse if it says "Dont shop here!".
- PageRank - the famous (as in "Hey, let's build a multi-billion dollar business based on this" famous) ranking algorithm that gave rise to Google. It uses both link text and link count to measure the importance of a url.
- Neural network score - Use a neural network in order to factor in user clicks in how popular a url is given a user query. If users searching for "bank" really often click the wikipedia entry on Functional Programming, this way of ranking would move the url of this entry higher despite all the other ranking functions scoring it pretty low.
The scoring methods can be changed by changing the weights list on line 287.
Neural Networks
April 10th: This part will be finished when I wrap my head around back propagation in Andrew Ng's machine learning course.
Scoring search results is a great example of what a neural network can be used for. As far as I understand, neural networks are great at producing very flexible solutions because they can be "trained" and work well with many features. I've seen examples of using neural networks for hand written digit recognition (Andrew Ng's own machine learning course homework assignment) as well as for self-driving cars. Great stuff.
The way a neural network works is by having nodes, which themselves have weights. Forward propagation means "pushing" features (in this case - query words) through the nodes to obtain a score between -1 and 1. The higher the score, the more important a url is deemed for this query. Back propagation is more complicated, but in essence it takes the url that the user clicked and runs it backwards through the neural net, changing the weights. Next time someone uses the same query, the neural network will rank a url higher or lower depending on the previous action. I highly recommend taking Andrew Ng's course since it explains these networks in a much clearer fashion and gives more insightful details.
Comments